Abstract
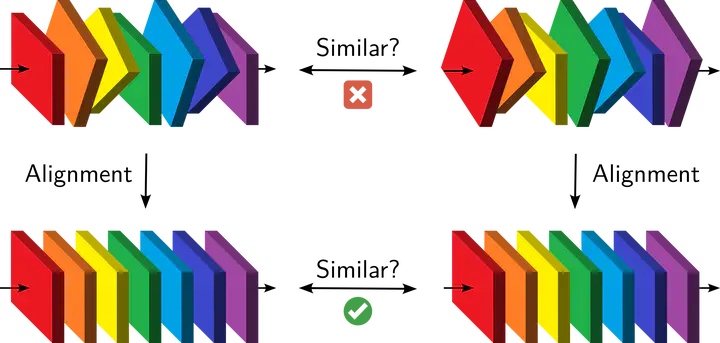
What do neural networks learn? A major difficulty is that every training run results in a different set of weights but nevertheless leads to the same performance. We introduce a model of the probability distribution of these weights. Layers are not independent, but their dependencies can be captured by an alignment procedure. We use this model to show that networks learn the same features no matter their initialization. We also compress trained weights to a reduced set of summary statistics, from which a family of networks with equivalent performance can be reconstructed.
Resources:
- Original paper with the mathematical model
- New: Shorter follow-up paper with a summary of the main ideas and an application to comparisons across training datasets
- Code used to produce all of our results (aligning and comparing weights of networks, sampling new weights, etc)
- Tutorial to reproduce some of our results in a self-contained, simplified setting
- Video of my talk at Youth in High Dimensions 2024 (ML/physics audience)
- Video of my talk at the AI and Pure Maths conference of IMSA (maths audience)
- Video of my talk at DeepMath 2023 (ML/maths audience)
- Keynote at the CCN 2023 conference with Mick Bonner (neuro/cogsci audience)
Florentin Guth
Postdoctoral Researcher in Science of Deep Learning
I’m a Faculty Fellow in the Center for Data Science at NYU and a Research Fellow in the Center for Computational Neuroscience at the Flatiron Institute. I’m interested in improving our scientific understanding of deep learning, e.g., explaining how it escapes the curse of dimensionality, particularly in the context of image generative models.